LeetCode3:Longest Substring Without Repeating Characters(无重复字符的最长子串)
LeetCode:https://leetcode.com/problems/longest-substring-without-repeating-characters/
LeetCodeCn:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
题目说明
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例
- 示例 1:
- 输入: “abcabcbb”
- 输出: 3
- 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
- 输入: “bbbbb”
- 输出: 1
- 解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
- 输入: “pwwkew”
- 输出: 3
- 解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,”pwke” 是一个子序列,不是子串。
解题方法
日常暴力法
遍历每个元素作为一个字符串开始,查找当前字符串是否元素不重复,如果不重复则得到其长度,全部遍历得到其最长无重复自串长度.
滑动窗口(HaskMap辅助表)
HaskMap真是个好东西,最近再整理下HashMap相关的资料
此方法只需要一次遍历即可,主要思路为在遍历过程中计算当前遍历位置到最后一个重复元素的下一位位置的长度(也可以说是将最后一次重复的元素的下一位作为一个子串的开始,当前遍历位置作为子串的结束,计算此子串的长度),将其与已存在的最长子串长度对比,得到当前最长未重复元素子串的长度.下面通过图示解析相关思路.
图解相关思路
我们输入”pwwkew”作为参数,此时默认最长无重复子串长度(result)为0,HashMap辅助表check为空.

默认遍历位置i = 0, 默认最后一个重复元素的下一位位置index = 0;
查找辅助表check中不存在i位置对应的元素p
当前最长无重复元素子串长度result = i(0) - index(0) + 1 = 1
更新check表,将(p,0)加入到check表中
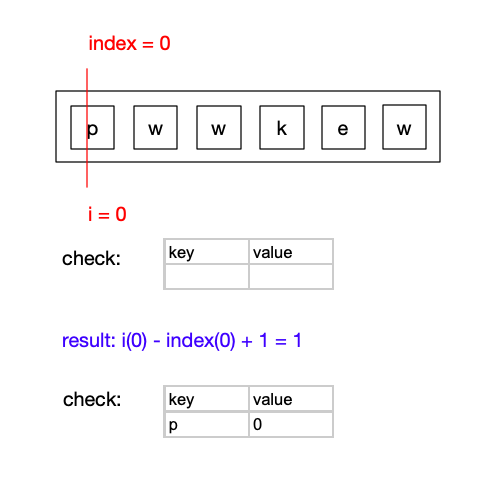
继续遍历此串,当i = 1时,check中依旧查找不到i位置对应的元素w
result = i(1) - index(0) + 1 = 2
更新check表,将(w,1)加入到check表中
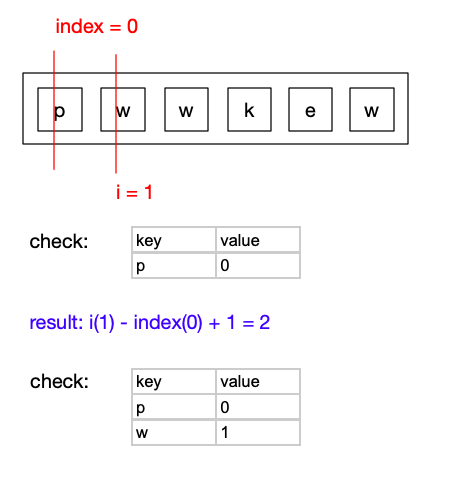
继续遍历当i = 2时,此时i对应的元素w在check表中可以被找到,说明此元素是一个重复元素,我们需要更新index的值,在这里我们比较当前index的值和check中出现的最后一次重复元素的下一位中的较大值(防止”abba”这样的在遍历最后一个a的时候取到首位a的位置).
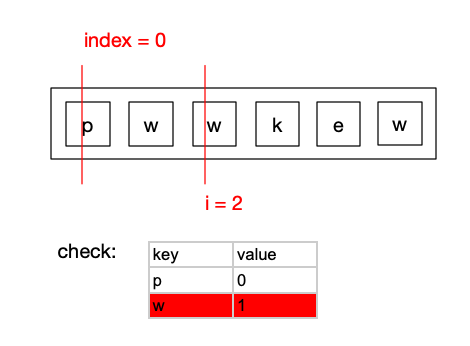
此时index = max(index(0), check.get(key(“w”)) (1 + 1 = 2)) = 2
计算当前的result = i(2) - index(2) + 1 = 1,小于之前的result(2),此时result依然为2.
更新check表的内容,将key为w的value更改为2
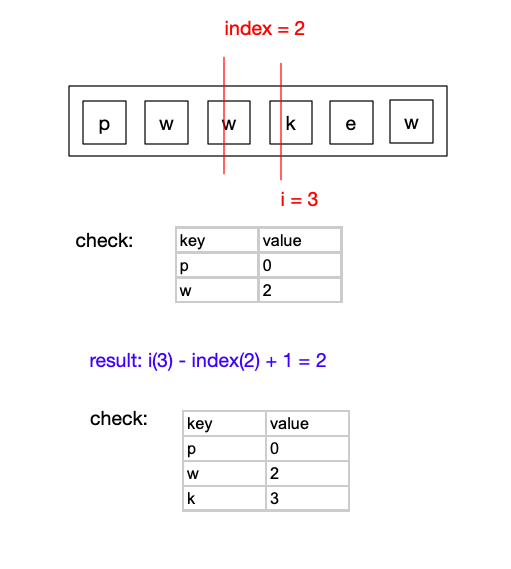
继续遍历,当i = 3时,check表中找不到’k’
result = i(3) - index(2) + 1 = 2
更新check表,将(k,3)加入到check表中
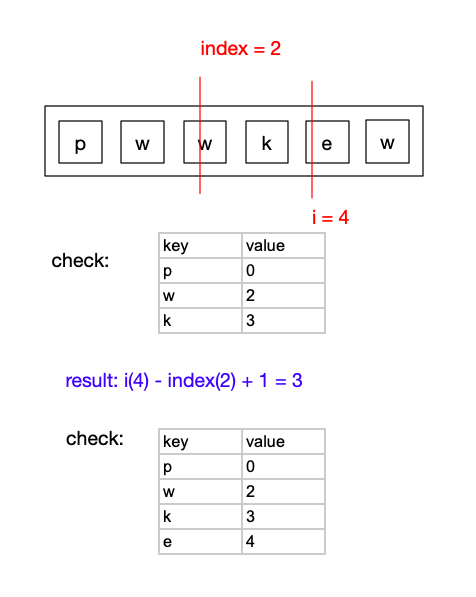
继续遍历,当i = 4时,check表中找不到’e’
result = i(4) - index(2) + 1 = 3, 此时的result大于原有的result,则更新result的值为3
更新check表,将(e,4)加入到check表中
继续遍历当i = 5时,此时i对应的元素w在check表中可以被找到,
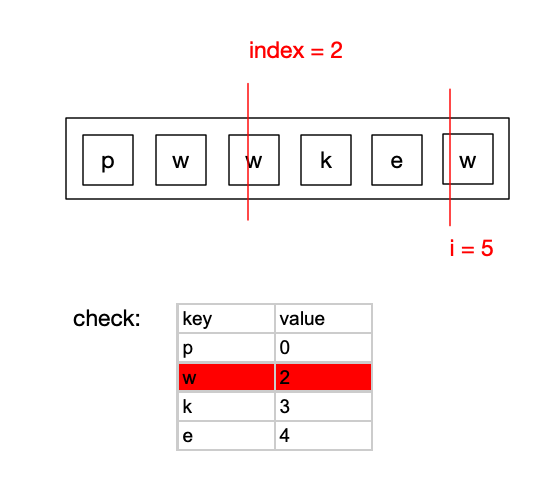
此时index = max(index(5), check.get(key(“w”)) (2 + 1 = 3)) = 5
计算当前的result = i(5) - index(2) + 1 = 3,大于之前的result(2),此时result更新为3.
更新check表的内容,将key为w的value更改为5

至此,遍历结束,此时reslut的值就是s中最长为重复子串的长度.
代码实现
1 | public int lengthOfLongestSubstring(String s) { |
相关代码欢迎大家关注并提出改进的建议